Hi, I am trying to use Flowers on Docker with the following setup:
4 clients
Resnet34 as model
CIFAR100 as dataset
Flower 1.22.0
However, I noticed that, when big models such as Resnet34+, some clients tend to fail ( the training keeps going on but with only a portion of the clients). By inspecting the containers “supernode-n” in the docker deployment, where n is the client number, I noticed the the failed clients present this error:
Hi @eliafaure , thanks for creating the post. I note from the log that this happened on run 47. Is it always happening after a number of rounds or also earlier in the training process? Were you able to observe something failing on the SuperLink side just before that error on the SuperNode was shown ?
Hello @javier, thank you for your reply.
I had originally modified the time.sleep(3) command in the start_client_internal and grpc_grid files, reducing it to time.sleep(0.1). I discovered that after restoring it to the original value, the frequency of supernodes failures decreased significantly, but it is not completely eliminated.
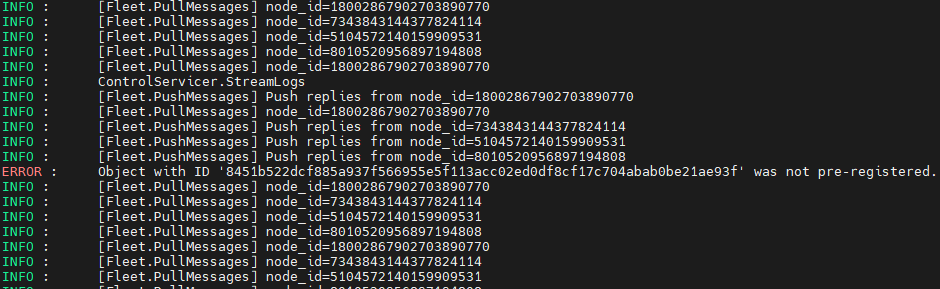
In any case, the error showed in the superlink is the following:
These failures occur now sporadically, and the affected round number is highly variable (sometimes it appears within the first 10 rounds).
More in general, it also happens sometimes that a message from a client is not properly received by the aggregator, resulting in only partial results being recorded (e.g., receiving 3 results and 1 failure). In these cases, the clients do not fail permanently; in the following round, all clients are again available, and the process continues normally. Over a training of 100 rounds, I usually observe it 3/4 times in total.
thanks for providing additional details! Do you frequently see reconnection attempts between your SuperExec and the SuperNode? I’m assuming you are running your SuperNode with --isolation=process?
Have you observed the ERROR: Object with ID '....' was not pre-registered when connection wasn’t lost between the different components in your federation ? (i.e. when you don’t see any of those WARNING: Connection attempt ...)
yes, I am running all supernodes and superlink container with --isolation process.
If there is no permanent failure of the SuperNode, I never see reconnection attemps. Also, to the best of knowledge, I have never seen the message “ERROR: Object with ID ‘…’ was not pre-registered” when connection wasn’t lost.
In general, it seems that, during training, “ERROR: Object with ID ‘…’ was not pre-registered” causes the connection failure.
Hi @eliafaure , thank you for the extra details. We’ll investigate this.
It seems that the first stage of communicating a message (which does the object pre-registration – you can thing of “objects” as the serialized blobs that comprise a RecordDict, which is the payload type of all Message objects) fails. But even though it fails, the second stage of communicating a message (i.e. actually pushing all the serialized blobs) goes ahead triggering the ERROR: Object with ID ... was not pre-registered you observe.
Did you observe any of these errors also in the SuperNode container? or only in the SuperLink one?
The error ERROR: Object with ID ... was not pre-registered usually appears in both superlink and supernodes, but the superexec-serverapp container does not report any error (it shows simply “received 3 results and 1 failure”). The superapp, instead, shows the error in the last picture of my last message.
I also modified a bit the code by inserting a new line in the start_client_internal file, for tracking the communication time:
Inserting the receiving_time into the contexts shouldn’t cause this issue (which is more related to the transmission of Messages over a, apparently, unstable network).
I’ll follow up with some questions while I investigate this issue.
Hello @eliafaure , one quick question. Did you also observe the NoObjectInStoreError: Object with ID ... was not pre-registered issue in the container running the SuperExec with the ClientApp plugin (i.e. the service running the clientapp)
Or did you only see it in the SuperLink and SuperNode containers?
Hi @eliafaure ! Just following up — we’re still investigating this issue. It’s been a bit difficult for us to reproduce the errors you’ve described. We tried using some tools to simulate poor network conditions, but so far we haven’t been able to observe the same behavior.
While we continue our investigation, could you please share a few more details about your setup? Specifically, what is the connection between SuperLink and SuperNode like — for example, typical latency, bandwidth, and packet loss rate?
Also, can we assume that the connections between SuperExec and ClientApp ⇄ SuperNode, and between SuperExec and ServerApp ⇄ SuperLink, are stable? Or are all of these links experiencing instability?
Right now I am using a 3 clients scenario. I am applying traffic control on the connectioon Superlink ⇄ Supernode , but the connnections Superexec-clientapp⇄ Supernode and Superexec-serverapp⇄ Superlink are stable.
In particular, I am limiting the bandwidth to values that range from 120Mbps to 1Mbps, and adding a variable delay between 5 and 600 ms. The conditions of the network change randomly every 10/20 seconds.
Unfortunately, I do not have the records of the precise values when the failure happens, but I can try to check them if needed.
Let me know if you need further details, and many thanks for your help.
Hello @eliafaure , we found the issue and we are happy to say that it’s solved in Flower 1.24.0 (released a couple of days ago). The issue was due to an extremely rare event where by while object registration process was taking place at the LinkState a SuperNode would ask to pull such objects. Registering objects takes just a handful of milliseconds but this could take longer if the file system is slow.