
It’s great having you taking part in the Decentralized AI Hackathon!
This post provides you with the minimal set of instructions so you can take part in (and possibly win!) the Decentralized AI Hackathon ![]() !
!
Preparations
-
Join the Flower Slack workspace, then head over to
#hackathon_stanford_2025. In addition to announcements about the Hackathon, you can use the Flower Slack to connect with other distributed AI enthusiasts. -
Register at Flower.ai by clicking the Sign up button in the top-right corner. A Flower account is required to run your Flower Apps remotely through a federation of virtual hospitals/clinics we have set up for this hackathon.
Flower Warmup
Here are a couple of tutorials about how to get started with Flower. Even if you have been using Flower for years, you may want to take a look at them because the Flower APIs keep maturing and gaining functionality. You don’t need to read them all; these are just a small selection of the many tutorials and how-to guides available in the Flower Documentation for your reference.
- Quickstart tutorial (~15min tutorial)
- The Flower Tutorial (~2h tutorial, 5 pages)
- Run Flower with Deployment Engine
- Update your Flower Apps to the
Message API– useful if you have an existing Flower App that you want to use as a starting point. - Advanced PyTorch example
![]() While PyTorch is the ML framework used in the resources above, Flower is framework-agnostic. This means that you can use it with many other ML toolkits (e.g. TF, JAX, MLX, Pandas, etc). There are no fundamental changes on how you write Flower Apps when using different frameworks. Please refer to either the quickstart-tutorials or the examples on GitHub to see Flower using all popular ML frameworks.
While PyTorch is the ML framework used in the resources above, Flower is framework-agnostic. This means that you can use it with many other ML toolkits (e.g. TF, JAX, MLX, Pandas, etc). There are no fundamental changes on how you write Flower Apps when using different frameworks. Please refer to either the quickstart-tutorials or the examples on GitHub to see Flower using all popular ML frameworks.
Tracks
There are three tracks for the hackathon. You can take part in one or several. Prizes are not tied to specific tracks.
For tracks 1 and 2, the expectation is similar: first, you learn from distributed data using Flower; then, you build a service/product that makes use of the trained model. Track 1 is more guided in the sense that the choice of dataset (and overall theme of the demo as a result) has been made for you. In track 2 you have total freedom.
Track 1: Decentralized Training
In this track you’ll be able to interface with a Flower federation of virtual clinics, each containing a number of medical images spanning different pathologies. You’ll be given a basic Flower App that federates the training of a small CNN on one of the datasets available. Your task is to (1) improve the app so the resulting model on one or all the datasets (five in total) performs well; and (2) take the resulting model and build a service (web, app, something else?) that brings value to society.
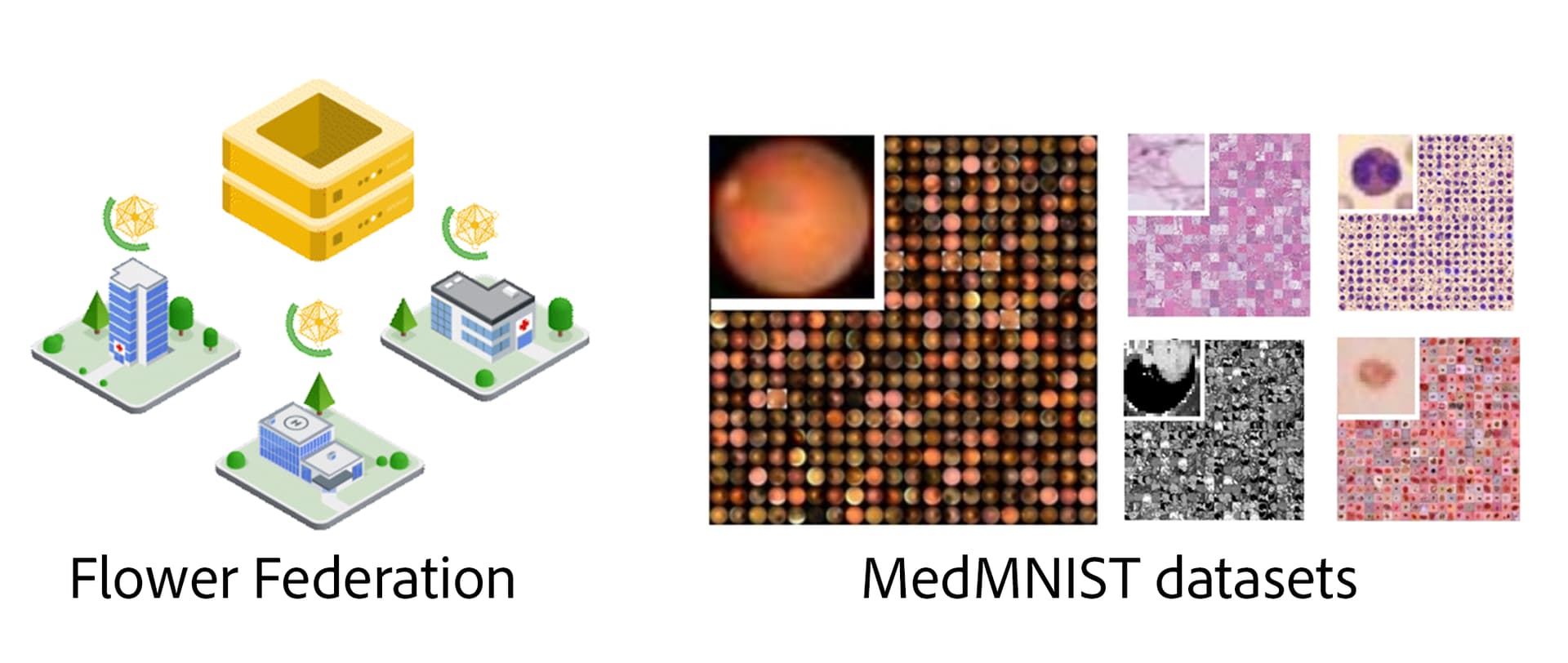
Virtual Federation setup:
- There are 8 virtual nodes connected.
- Nodes have no GPUs, only CPU workloads are able to run.
- Nodes won’t accept messages from runs running for longer than 15mins. In other words, your run will be terminated after 15mins.
- Nodes contain data from five MedMNIST datasets. Concretely:
PathMNIST,DermaMNIST,RetinaMNIST,BloodMNISTandOrganAMNIST. The image sizes are64x64and RGB (except forOrganAMNISTwhich is grayscale). - Each dataset has been partitioned into 8 heterogeneous splits using Flower Datasets, one per virtual clinic.
How to run your app across the federation?
Clone the base app repository and follow the instructions in the readme.
git clone https://github.com/yan-gao-GY/Flower-Decentralized-AI-Hackathon.git
Track 2: Open-ended Decentralized Revolution
Already have an idea in mind? This track invites you to tackle ambitious, open-ended challenges or propose entirely new use cases that unlock the full potential of distributed data. With Flower, you can implement your solution on any dataset — including your own — and showcase the power of decentralized learning.
You can choose to:
-
Use Flower’s Simulation Engine to model large federations on a single machine (your laptop or a cloud GPU server). If you need to partition your dataset, you may want to use Flower Datasets but you don’t have to. You may want to take a look at the Flower Simulations documentation.
-
Or deploy directly on a real-world federation of devices such as laptops, embedded systems, or servers. You’ll be using Flower’s Deployment Engine for this, following this deployment guide. You may find useful the Flower Architecture and Flower Network guides.
With Track 2, you don’t need to access ResearchGrid—you can run simulations locally or deploy Flower for a proof of concept. We’re excited to see your creativity in action! To spark ideas, here are a few example project directions:
The following are just examples to spark ideas for Track 2. You are not limited to only these directions.
-
Unlocking Vertical Federated AI
In many real-world scenarios—like banks with financial data and hospitals with health records, or retailers with purchase history and telecoms with location data—different organizations hold different features about the same users. Vertical federated learning enables secure combination of those complementary datasets without sharing raw data. By aligning user IDs and learning across feature spaces, richer models can be trained while preserving privacy and enabling cross-organization collaboration. -
Automated Data Harmonization
In federated learning, data for the same use case often exists in different formats. For example, hospitals collect medical images using different protocols, or banks have tabular datasets naming the same features differently. There is a need to automatically detect and align schema, semantics, and modalities (tabular, images, etc.) so data becomes interoperable across participants. The result: less manual preprocessing, faster collaboration, and stronger global models. -
Rewarding Federated Contributions
A system by whichSuperNodesin a federation are rewarded based on their contribution to the global model. In Flower, theSuperNodesare the long-running processes that sit where the data is and execute theClientAppof a Flower App. There are different ways to measure the contribution of aSuperNodeto the model being federated. For example, based on the amount of local data such model learns from, how long it takes to perform such training, the quality of such data, etc.
Track 3: Decentralized Open-Source Infrastructure
Flower thrives thanks to its open-source community. We’ve prepared a list of features that many in the Flower community would love to see. Some of these topics are easier than others, but all are relatively self-contained and could be accomplished in a single or a few PRs.
To take on a task, please open a GitHub issue with the title format:
“Hackathon: ”
for example, “Hackathon: Weights & Biases Mod”.Multiple participants or teams may work on the same topic. However, we recommend checking first to avoid oversaturation, as we will only be able to merge the best solution.
-
Weight & Biases Mod
Create a self-contained mod that streams metrics in outgoing messages to Weights & Biases (W&B) from theClientApp.Useful links: What are Mods,
arrays_size_modsource code -
Strategy Wrapper for W&B
Create a Strategy wrapper that automatically streams all metrics to W&B.- Log the
MetricRecordfrom the return of<strategy>.aggregate_train(). - Log the
MetricRecordfrom the return of<strategy>.aggregate_evaluate(). - Log the
MetricRecordfrom the return ofevaluate_fnpassed to the<strategy>.start()method.
Useful link: Strategy abstraction.
- Log the
-
Model Compression Mod + Strategy Wrapper
Develop a mod that compresses all models (ofArrayRecordtype) in outgoing messages and decompresses all models in incoming messages.In addition, build a companion Strategy wrapper that compresses models in instruction messages from
<strategy>.configure_train, and decompresses models in messages fromClientApps in the wrapped<strategy>.aggregate_train.Useful link: What are Mods,
arrays_size_modsource code, Strategy abstraction. -
VFL Example: Vertical Logistic Regression
Create a Flower example project that demonstrates Vertical Logistic Regression on a typical tabular dataset. You will need to partition the dataset vertically (i.e., by features) as part of the setup. -
FedBufStrategy
Implement the strategy based on the FedBuf paper.- Requires understanding the Strategy abstraction.
- Override the
.start()method to achieve asynchronicity. - Hint: use
Grid.push_messagesandGrid.pull_messagesfor non-blocking asynchronous communication.
-
Miscellaneous Contributions
- Alphabetically sort arguments for
flower-xyzCLI commands. - Improve how strategies log their configuration at the beginning of the
<strategy>.start()method. - Have another idea? Talk to a member of the Flower team during the hackathon before starting!
- Alphabetically sort arguments for
If you’re keen on contributing to Flower, please refer to the contributor guide. We kindly ask that you include unit tests with your PRs. We aim to have your PRs merged by the end of the hackathon or shortly afterwards.
Preparing for the Demo
At 6:30pm the judges will evaluate all the demos from teams or individuals that wish to compete for one of the prizes. Each team/individual will have a maximum of 1 minute to present and run the demo followed by one/two questions from the judges. Each demo will be rated based on their impact, innovation, usage of Flower and delivery.
More details will be shared during the Hackathon kick-off session.
FAQ
Where is the Agenda for the Hackathon?
You can find the complete schedule in the Hackathon page at flower.ai.
Can I ask questions to the Flower team?
Yes! We are more than happy to answer any questions you may have. Just walk up to any Flower team member and ask directly.
Is there any time limit for using ResearchGrid?
Yes. Each run you submit via the flwr run command has a 15-minute TTL, starting from when your run switches to the “running” status.
How many runs can I submit to ResearchGrid?
ResearchGrid allows up to 5 concurrent runs per user, including runs in “pending”, “starting”, and “running” statuses. You can check your submitted runs with the flwr ls command.
If you want to stop a run early to free up space for a new one, use the flwr stop <run-id> command to stop the selected run.
What are the prize evaluation criteria?
All finalist demos will be evaluated by the judges. Model performance is not the sole or decisive factor. Each demo will be assessed based on:
- Impact – the potential value and usefulness of the solution
- Innovation – originality and creativity in the approach
- Use of Flower – how effectively Flower is applied
- Delivery – clarity, completeness, and quality of the demo
Is there a size limit for what I can save?
You can save results to the output directory, which will be uploaded to our artifact store at the end of a run and later retrieved with flwr pull --run-id <run-id>. The output directory is provided in ServerApp via context.node_config["output_dir"].
There is a 900 MB limit per run on what you can save. That said, saving artifacts is usually unnecessary—you don’t need to save anything in most cases to participate in or win the Hackathon.